


Las TPU de Google son la primera gran señal de que el imperio de NVIDIA está tambaleándose – El diario andino




Corría el año 2013 y Jeff Dean, uno de los directores de Google, se dio cuenta de algo junto con su equipo: si cada usuario de Android utilizara su nueva opción de búsqueda por voz durante tres minutos al día, la empresa tendría que duplicar el número de centros de datos para hacer frente a la carga computacional. En ese momento, Google utilizaba CPU y GPU estándar para esta tarea, pero entró en pánico y se dio cuenta de que necesitaba crear sus propios chips para esas tareas.
Así nació La primera unidad de procesamiento tensorial (TPU) de Googleun ASIC diseñado específicamente para ejecutar las redes neuronales que impulsaban sus servicios de voz. Eso creció y creció y en 2015, antes de que el mundo se diera cuenta, esos primeros TPU aceleraron Google Maps, Google Photos y Google Translate. Una década después, Google ha creado TPU tan potentes que casi sin querer se han convertido en una solución sorprendente y amenaza inesperada para la todopoderosa NVIDIA. Ahí no hay nada.
Bendito pánico.
Los TPU de Google cumplen su promesa
Hasta ahora, cuando una empresa de IA quería entrenar sus modelos, recurría a chips avanzados de NVIDIA. Eso ha cambiado en los últimos tiempos y, de hecho, hemos visto dos señales recientes que sin duda suponen un punto de inflexión.
El primero fue el lanzamiento de Claude Opus 4.5, un modelo excepcional, sobre todo en tareas de programación. Los responsables de Anthropic ya ellos explicaron que este nuevo modelo no depende sólo de NVIDIA, sino que combina la potencia de tres propuestas diferentes: la de NVIDIA, pero también la Trainium de Amazon y las TPU de Google.
Pero también es que Google ha dado la campana porque su flamante modelo de IA Gemini 3 ha sido entrenado exclusivamente utilizando los nuevos TPU Ironwood que fueron presentados en abril y se han convertido en una auténtica sensación.
Como decíamos, Google inició ese proyecto en 2013 y lanzó su primera TPU en 2015, pero esa necesidad interna se convirtió en una bendición, porque lo que Google no podía saber es que esas TPU acabarían llegando en el momento adecuado: el lanzamiento de ChatGPT las convirtió en una oportunidad fantástica para reforzar su infraestructura de IA, pero también para utilizarlas para el entrenamiento e inferencia de sus modelos de IA.
De ahí acabamos llegando a los actuales TPU Ironwood, que en su séptima generación son excepcionales tanto en inferencia como en entrenamiento (como ha demostrado su uso para Gemini 3).
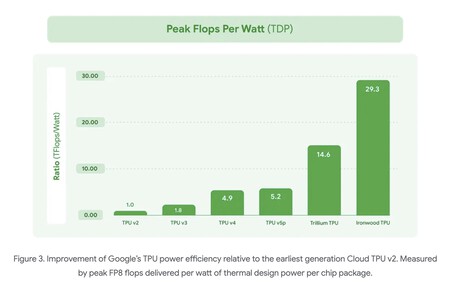
La eficiencia y potencia de estos chips da un salto muy notable en comparación con sus predecesores y, por ejemplo, logran Doble rendimiento de FLOPS por vatio lo cual se logró con chips Trillium.
Si los comparamos con los TPU v5p de 2023, los chips consiguen alcanzar los 4.614 TFLOPS, 10 veces más que los 459 TFLOPS de aquellos modelos de hace dos años. Es un salto extraordinario en rendimiento (y eficiencia).
La clave para 2025: Google ahora deja que otros utilicen sus TPU
Pero en la evolución de las TPU hay otro elemento diferenciador en 2025. Este ha sido el año en el que Google ha dejado de «ser egoísta» con sus TPU. Antes sólo ella podía utilizarlos, pero en los últimos meses ha llegado a acuerdos con OpenAI —que también busca fabricar sus propios chips— y especialmente con Anthropic.
Esa segunda alianza es especialmente monumental como parte de esa estrategia de subcontratación. Google no sólo alquila capacidad en su nube, sino que facilita la venta física de hardware. El acuerdo cubre un millón de TPU: 400.000 unidades de su Ironwood TPUv7 vendidas directamente a través de Broadcom y 600.000 alquiladas a través de Google Cloud (GCP).
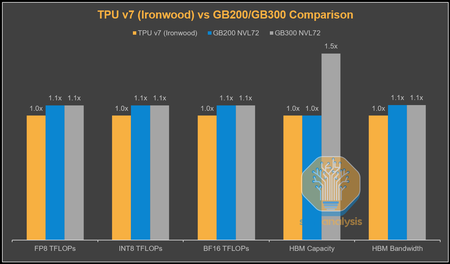
en un informe profundo en SemiAnálisis Se revela cómo, desde una perspectiva técnica, el TPUv7 Ironwood es un competidor formidable. La brecha de rendimiento con NVIDIA se está cerrando y El TPU de Google es prácticamente igual al chip Blackwell de NVIDIA en FLOPS y ancho de banda de memoria.
Sin embargo, la verdadera ventaja reside en el coste. Se estima que el coste total de propiedad (TCO) de un servidor Ironwood es un 44% menor para Google que para un servidor NVIDIA GB200, lo que permite al gigante de las búsquedas ofrecer precios muy competitivos a clientes como Anthropic.
Para ayudar aún más en esa carrera, señalan en SemiAnalysis, Google tiene otro as bajo la manga. Se trata de Inter-Chip Interconnect (ICI) de Google, una arquitectura de red que permite conectar hasta 9.216 chips Ironwood utilizando una topología toroidal 3D.
Google también utiliza conmutadores de circuitos ópticos que permiten enrutar datos ópticos sin conversión eléctrica, lo que reduce tanto la latencia como el consumo de energía. Esto le permite reconfigurar la topología de esa red sobre la marcha para evitar (o mitigar) fallas y optimizar diferentes tipos de paralelismo.
El «foso» de NVIDIA con CUDA se está reduciendo
A menudo hemos repetido que, aunque los fabricantes de semiconductores ya tienen chips llamativos (dígaselo a AMD), en realidad la verdadera fortaleza de NVIDIA está en CUDA, la plataforma de software que se ha convertido en el estándar de facto para los desarrolladores e investigadores de IA.
Google también quiere cambiar las cosas aquí. Durante los últimos años, la empresa intentó centrarse en bibliotecas de Python como jax cualquiera XLApero en los últimos tiempos ha comenzado a priorizar el soporte nativo de PyTorch —gran competidor de TensorFlow— en sus TPU.
Esto es crucial para facilitar que los ingenieros y desarrolladores comiencen a migrar a sus TPU en lugar de a las GPU NVIDIA. Antes era posible usar PyTorch en las TPU, pero era engorroso, como si uno tuviera que hablar un idioma usando un diccionario en tiempo real, mientras que para las GPU de NVIDIA ese era el idioma «nativo».
Con XLA Google utilizó una biblioteca intermedia como traductor para poder utilizar PyTorch, pero eso fue una pesadilla para los desarrolladores. El soporte nativo permite que las TPU de Google se comporten como las GPU de NVIDIA a los ojos del desarrollador.
El otro gran avance que está haciendo Google en el apartado de software va dirigido a soporte del ecosistema de inferencia abierto. Aquí, vLLM y SGLang son como un motor de alto rendimiento para un auto de carreras: estas bibliotecas de software le permiten ejecutar modelos de IA de manera eficiente y económica, y se ejecutan de manera estándar en las GPU NVIDIA.
La solución de Google para poder utilizar vLLM fue nuevamente tomar ese código y traducirlo en tiempo real a JAX, algo que resultó ineficiente. No hubo optimización, pero Google sí. abordando ese problema con un grupo de trabajo que vuelve a proponer un soporte mucho más «nativo» en las TPU de Google. Esto actualmente se encuentra en pleno desarrollo, pero también se pretende “acortar el foso” que tiene NVIDIA y que es una baza importante para seguir dominando este mercado.
Por lo tanto, nos enfrentamos a un posible giro de los acontecimientos en el mundo de los fabricantes de chips de IA. La situación actual de Google la sitúa claramente como la amenaza más grave para NVIDIA hasta la fecha.
Ya no estamos ante un proveedor de infraestructura en la nube que optimiza sus propias cargas de trabajo, sino más bien una empresa que vende soluciones completas y que ofrece mejor rendimiento por dólar, mayor escala de red y una hoja de ruta prometedora en el campo del software.
Nvidia tener problemaspor supuesto. Veremos cómo reacciona.
En | El problema de AMD no es que no produzca buenas GPU para IA. Ni siquiera está cerca de NVIDIA





{kind=link}